Internal linking has always been one of those SEO fundamentals that gets mentioned in every checklist and then, largely, ignored. It sits below the fold of most audits as something to fix if you have time, after the title tags and the schema and the Core Web Vitals.
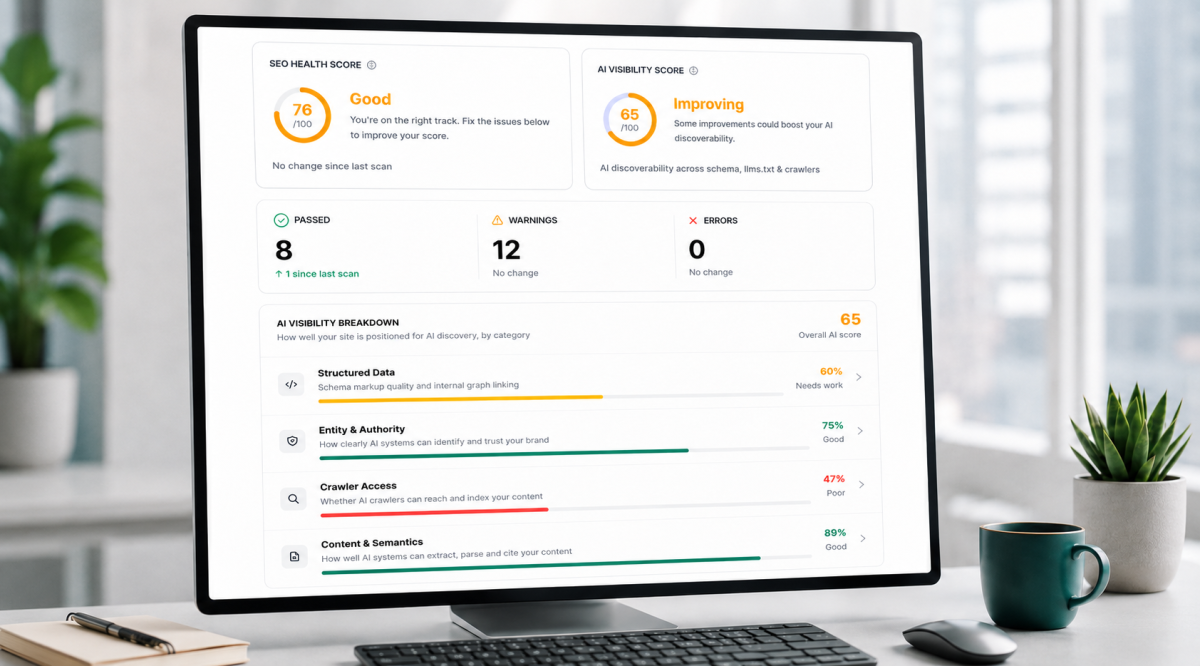
Going forwards, every SEO scan includes an Internal Link Quality analysis. It runs across nine separate checks, each designed to answer a specific question about whether your links are doing the work they should be doing — for search engines, for AI-powered discovery systems, and for the people actually reading your pages.
Why internal linking is more important than ever
For most of the last decade, the internal linking conversation was dominated by PageRank flow — the idea that authority passes between pages via links and that you can sculpt rankings by controlling those paths. Now two newer pressures have pushed internal link quality up the agenda.
Crawl budget
Google has been increasingly transparent about the fact that it cannot crawl everything, and that the structure of your internal links directly influences which pages get discovered and how often. Google's crawling process begins with discovering URLs through multiple pathways — XML sitemaps, internal links, external references, and previously crawled pages. If a page isn't reachable via a well-connected internal link path, it may be discovered late, crawled infrequently, or not crawled at all.
Discovered — currently not indexed" means Google knows the URL exists but has decided it isn't worth the budget to crawl it yet. This is usually a sign of low site authority or poor internal linking.
The practical consequence is that internal links are not just helpful — they are the primary mechanism by which you control what Google sees and how often it sees it. If an important page is buried five clicks deep in your site's navigation, that's a problem. Google allocates more crawl attention to pages that are easily reachable from your homepage or category pages.
The emergence of AI crawlers
GPTBot, ClaudeBot, PerplexityBot, and a growing ecosystem of RAG systems are now crawling the web with a fundamentally different purpose to Googlebot. They are not just indexing pages for keyword matching — they are building semantic models of topic relationships, and your internal link structure is part of the input.
Every internal link influences that pipeline. Links help systems discover pages, but more importantly, they provide structural and semantic context that serves as metadata for embeddings and retrieval. When a set of chunks consistently links to one another with descriptive anchors, models gain higher confidence about the relationships those chunks encode.
Linking related pages together helps AI crawlers find important pages. The more internal links a page has, the more likely a crawler is to find it. Clear hierarchies and topic clusters signal how pages relate to one another, allowing AI systems to understand context.
A site that links well between related content is not just easier for Googlebot to crawl — it is better positioned to be understood, cited, and surfaced by AI-powered search and discovery systems.
What is RAG or Retrieval-Augmented Generation?
To understand why this matters beyond public search engines, it helps to know what RAG is. When a product like ChatGPT, Perplexity, or a company's internal AI assistant needs to answer a question using up-to-date or domain-specific information, it doesn't rely solely on what it was trained on. Instead, it fetches relevant documents from a knowledge base at the time of the query, reads them, and uses them to ground its answer. That fetching process is retrieval-augmented generation — the AI's answer is augmented by retrieved content. The "knowledge base" those systems pull from is often built by crawling websites, including yours, and following internal links to discover related pages. A well-linked site gives that crawler a richer, more connected picture of your content; a poorly linked one gives it fragments with no relationship to each other.
This is no longer an edge case. Enterprises are increasingly building RAG systems on top of third-party content — product documentation, supplier sites, industry resources — and the structure of those sites directly determines how well the AI can navigate and understand them. Your internal link graph is increasingly feeding not just public search, but also the AI systems that your customers, partners, and potential clients are using to find information.
What SiteVitals now checks, and why
Internal links present
The most basic check: does the page link to other pages on the same site at all?
A content page with no internal links is effectively an island. It may be reachable from other pages, but it contributes nothing to the discovery of the rest of the site. For crawlers arriving on that page for the first time — and AI crawlers discovering it via a sitemap or external reference — there is no signal about what other content exists or how this page relates to it.
This is a fail-level finding when it occurs on a content page. Navigation-only pages (login screens, error pages, single-CTA landing pages) may legitimately have few internal links, but for any informational page the absence of outbound internal links is an oversight worth fixing.
Contextual links in the main content
Having internal links is necessary but not sufficient. Where those links appear on the page determines how much semantic value they carry.
Contextual links are surrounded by relevant content, which gives them semantic value. Search engines can see what the page is about, what the linked page is about, and why the connection exists. A link from a paragraph discussing a specific topic tells a crawler something about the relationship between the two pages. A link in a footer, header, or sidebar repeats the same navigation that appears on hundreds of other pages — useful for discovery, but a much weaker topical signal.
Google treats navigation links as non-editorial links. The distinction matters because editorial, contextual links carry the kind of topical authority signal that Google uses to understand what a page is actually about. Footer links remain useful for functional purposes, but they carry less SEO weight than contextual links within main content.
SiteVitals classifies each internal link by its location in the DOM — <main>, <article>, <nav>, <header>, <footer>, <aside> — and flags pages where all internal links fall outside the main content area. A page with 40 internal links and zero contextual links is, from a topical signal perspective, significantly weaker than a page with 10 links and 6 in the content body.
Anchor text quality
Anchor text is one of the oldest signals in search, and it has remained relevant through every algorithm update because it is genuinely useful information. The words you choose for a link tell both crawlers and readers what the destination page is about.
Anchor text might look like a minor detail — a few underlined words in a hyperlink — but in the world of SEO, it carries serious weight. To Google, those clickable words signal what the linked page is about and why it matters.
Weak signal
Learn more about our services on our website. If you're interested, click here to find out more.
Strong signal
Our website uptime monitoring runs checks every minute and alerts your team before users are affected.
The check flags generic anchors as a warning rather than a failure, because a single "read more" link at the end of a content card is not a meaningful problem. It becomes a problem when it is the dominant pattern — when the majority of internal links use interchangeable text that tells crawlers nothing about their destinations.
For AI retrieval systems the signal is even more direct: when content chunks consistently link to one another with descriptive anchors, models gain higher confidence about the relationships those chunks encode.
Empty or inaccessible internal links
An internal link with no readable text and no accessible label — no aria-label, no title, no visible text — is invisible to both screen readers and crawlers. This is simultaneously an accessibility failure and a signal quality failure.
The most common cause is icon-only links: an <a href="/contact"> containing only an SVG icon, with nothing to describe the destination. If the link carries an aria-label="Contact us", SiteVitals treats it as labelled and does not flag it. If there is no accessible name at all, it is reported as empty.
This check aligns with the existing Interactive Semantics checks already in SiteVitals — specifically the icon-only link check — but focuses specifically on internal links, where the crawl signal consequence is most direct.
URL hygiene
This check looks at the structure of internal link URLs for patterns that create unnecessary ambiguity or noise.
- HTTP links on an HTTPS site
- If your site is served over HTTPS — which it should be — internal links using
http://create a mixed-scheme internal link graph. Crawlers will follow the redirect, but the signal is inconsistent and the redirect consumes a small amount of crawl budget unnecessarily. - Tracking parameters in internal URLs
utm_source,utm_medium,gclid,fbclid, and similar parameters belong on external links pointing into your site. Using them on internal links creates URL variants that crawlers may treat as distinct pages, dilutes canonical signals, and — if they end up indexed — can create thin duplicate content. Internal analytics tracking should use cookies or data layer approaches, not URL parameters.- Duplicate URL variants
/page,/page/,/page?ref=navare different URLs to a crawler even when they return identical content. Inconsistency in how you construct internal links makes it harder for crawlers to determine which version of a URL is canonical.
These are all flagged as warnings rather than failures — no individual hygiene issue is catastrophic — but they compound at scale. A site with thousands of pages linking to tracking-parameter-laden internal URLs has a genuinely noisier crawl graph than one that keeps internal URLs clean.
Broken internal links
According to a Semrush 2025 study cited by BrightSEOTools, 42.5% of all websites have broken internal links, making this one of the most common and impactful technical SEO issues.
The impact is twofold. First, broken internal links waste crawl budget. When Google's crawler keeps running into broken links on your site, it's hitting dead ends, wasting time and resources on pages that don't exist instead of finding and indexing your new, valuable content. Second, they sever the flow of page authority: broken links mean your pillar pages lose power and your cluster pages can't support each other.
SiteVitals validates a capped sample of internal links (up to 100 per scan) using the same service used for the existing broken links check. Results are classified as broken (404, 410), server error (5xx), connection error, or unverifiable — the last category covering cases where the server blocks automated requests without that necessarily meaning the link is broken.
Link volume balance
A page with 150 internal links, 140 of which are nav and footer boilerplate, has a very different crawl character to a page with 30 internal links, 20 of which are contextual.
This check only fires when the total internal link count is high (above 80) and the proportion of those links in boilerplate areas is very high (above 85%). It is a soft warning, not a failure, and most pages will never see it.
The concern is not with having navigation links — those are necessary and useful. It is with pages where the sheer volume of repeated navigation and footer links drowns out any contextual signal that might exist. Template-heavy CMS sites, sites with very large navigation menus, and sites with footer link matrices are the most likely candidates.
JavaScript-only navigation links
Links using javascript: hrefs, or <a> tags with no href at all, are not crawlable. They may function perfectly for human users with JavaScript enabled, but they do not provide a crawl path and they do not pass any authority.
This check fires only when the count exceeds five, because a small number of JS-only links is normal (modal triggers, onclick handlers). A large number suggests a navigation pattern that may be significantly under-serving crawlers — particularly relevant for sites that have migrated to SPA frameworks where JavaScript handles routing.
Most AI crawlers don't execute JavaScript. If your site heavily relies on client-side rendering, critical information could be invisible to these bots. Initial HTML is what counts.
How this fits into the broader picture
Internal link quality joins the existing checks in the Indexing & Crawling group in the SiteVitals SEO & AI audit, alongside HTTPS redirect, indexing status, mixed content, broken links, AI crawler accessibility, llms.txt, and XML sitemap quality.
The platform already checks whether AI crawlers are permitted in robots.txt, whether llms.txt is present and well-formed, whether schema is correctly structured for AI entity recognition, and whether content is formatted for AI extraction. Internal link quality now checks that once a bot arrives on a page, it can actually follow a meaningful path to the rest of your content.
For the last decade, internal linking has been a crawl and authority signal for public search engines. It is now also a structural input to a much broader class of AI systems. Getting it right matters more than it used to.

By Tom Freeman · Co-Founder & Lead Developer
Full-stack developer specialising in high-performance web applications and automated monitoring.