An XML sitemap is one of the last things most people think about when it comes to their website. It's just something that most CMS platforms generate automatically. You tick the box and move on. For the majority of sites, it is never really reviewed again - perhaps once when you submit it to Google Search Console, but that's probably it. But the audience for your sitemap has changed significantly recently, and it probably deserves more respect.
When XML sitemaps were introduced in 2005 as a joint initiative between Google, Yahoo, and Microsoft, they had one job: help search engines discover pages they might otherwise miss. That job still exists. But the crawlers reading your sitemap today include GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot, and a growing roster of AI systems that use sitemap data to find, inventory, and decide whether to surface your content in generated answers.
Cloudflare's crawler data showed AI crawlers generating over 50 billion requests per day across its network in early 2025, with GPTBot more than doubling its crawl share between 2024 and 2025. These systems use your sitemap the same way traditional search engines do: as a structured, authoritative list of the URLs you consider important. A clean sitemap is a signal. A dirty one is noise.
This article explains what we built into SiteVitals' new XML Sitemap Quality check, why each signal matters, and the evidence behind those decisions.
A sitemap is a declaration, not a directory
Before getting into the individual checks, it helps to be precise about what a sitemap is actually communicating to a crawler — because it is more than a list of URLs.
A well-formed sitemap is a declaration of intent. It tells crawlers: these are my important, canonical, publicly accessible pages. Anything included in it receives an implicit endorsement that it is worth crawling and indexing. Anything omitted may be discovered through link-following, but is not being actively flagged as significant.
Use sitemaps to signal which URLs matter now, not as a storage place for every URL you've ever published. This matters even more on large sites where crawl budget is tight.
That changes how you think about quality. The question is not simply "does a sitemap exist?" but "does it accurately represent the pages worth crawling, and is it clean enough to trust?" Those are different questions with different answers for a lot of sites.
The checks — and the reasoning behind each
1. Does the sitemap exist?
The most fundamental check. A missing sitemap is not catastrophic for a small, well-linked site — crawlers are capable of discovering pages through internal links alone. But it is a real gap for larger sites, for pages that are not well-linked internally, and increasingly for AI discovery systems that may not follow links as aggressively as traditional crawlers do.
AI crawlers access websites through four primary mechanisms: seed URL discovery, link following, sitemap parsing, and direct request. A site without a sitemap is relying entirely on the other three for its content to be found and indexed. For agencies managing client sites, the absence of a sitemap is also the kind of finding that is easy to miss precisely because it involves something that isn't there.
2. Is the sitemap declared in robots.txt?
Having a sitemap and having a discoverable sitemap are two different things.
Google's documentation is direct on this point: insert a Sitemap: directive in your robots.txt file, and Google will find it the next time robots.txt is crawled. The robots.txt file is typically one of the first things any crawler fetches, which means declaring your sitemap there gives every well-behaved bot — search engine or AI — an immediate pointer to it, without needing to guess at common paths or wait for a Search Console submission to propagate.
It is a non-grouping directive, meaning it applies globally regardless of which user-agent is being addressed — so it benefits all crawlers with a single line. A sitemap that only lives at /sitemap.xml with no robots.txt declaration is relying on convention rather than explicit signalling. Most crawlers will still find it. But it is an easy win that a lot of sites leave on the table.
3. Can the sitemap actually be fetched and parsed?
This sounds too basic to be worth checking. In practice, it catches real problems that produce no visible error anywhere on the site.
Sitemap files that return a 404. Files accidentally caught by a robots.txt rule. Malformed XML that cannot be parsed. Child sitemaps referenced in a sitemap index that have since been deleted. These are all common audit findings.
For sitemap indexes — where a parent file points to multiple child sitemaps organised by content type or date — partial failures are particularly easy to miss. A site might have ten child sitemaps, nine of which are healthy and one returning a 404. The sitemap technically works, but an entire category of content is being silently excluded from the crawlable inventory. SiteVitals fetches and validates each child sitemap individually, reports on failures, and surfaces the specific error encountered, because these issues do not announce themselves any other way.
4. Does the sitemap contain URLs?
An edge case that appears more often than it should, particularly on sites where sitemap generation is automated. A sitemap that exists, loads, and parses as valid XML but contains zero URL entries is providing no value to any crawler. The check is cheap and the finding is unambiguous.
5. Is the current page included?
Not every URL needs to be in a sitemap. Pages that are intentionally excluded — thin content, pagination, internal search results — should not be there. But for a page that is being actively monitored and treated as important enough to run a full SEO and AI audit against, its absence from the sitemap is worth flagging.
Sitemaps are typically generated from database queries or CMS rules that can silently exclude content: a new content type that does not match the generation rules, a taxonomy page that falls outside the configured path patterns, a recently migrated URL that has not been re-added to the generation logic. All of these produce the same symptom — the page exists, it is indexable, but crawlers have not been explicitly told it matters.
On large sitemap indexes, getting this check right requires fetching every child sitemap, not just the first one. If the primary URL collection pass hits a processing limit, SiteVitals runs a targeted search across the remaining un-fetched child sitemaps rather than returning a false negative based on an incomplete sample.
6. Do the sampled URLs actually respond?
A sitemap is a promise to crawlers that the URLs it contains are worth visiting. Broken entries — 404s, 410s, persistent server errors — break that promise, and they erode the sitemap's credibility as a signal over time. The consistent best practice guidance is to include only canonical, indexable URLs: no noindex pages, no redirect destinations, no 4xx entries. A sitemap that regularly points to broken URLs teaches crawlers to treat it as unreliable.
Because validating every URL on a large site during a scan is not practical, SiteVitals checks a representative sample of up to 100 URLs using the same link checking logic that powers the existing broken links report. Results that cannot be verified — because a host is blocking automated requests — are reported separately as unverifiable rather than treated as broken, to avoid false positives on hosts with aggressive bot-blocking policies.
7. Are all URLs using HTTPS?
If a site is served over HTTPS, HTTP URLs in the sitemap represent a consistency problem. Crawlers following those entries will typically be redirected to the HTTPS equivalent, which is a minor inefficiency in itself. More to the point, it suggests the sitemap is either outdated or not being generated from the site's canonical base URL, which raises questions about the accuracy of everything else in it.
This tends to appear after domain migrations or HTTPS upgrades where the sitemap generation configuration was not updated. Nothing visibly breaks — pages still load, redirects still work — but the sitemap is quietly misleading every crawler that reads it.
8. Are all URLs from the expected domain?
A sitemap should only contain URLs from the site it represents. External domain URLs in a sitemap can indicate a misconfigured plugin, imported content without URL rewriting, or a multi-domain setup where sitemaps have been incorrectly combined. SiteVitals uses the same internal-domain logic applied elsewhere, accounting for legitimate subdomain variations, to avoid flagging deliberate structures incorrectly.
9. Are there duplicate URLs?
There is no scenario in which the same URL appearing twice in a sitemap provides useful information to a crawler. What it does is waste crawl budget — asking crawlers to schedule the same work twice. On large sites where crawl budget is a genuine constraint, duplicate sitemap entries compound with other inefficiencies to slow down how quickly updated content gets re-indexed.
Duplicates most often originate from sitemap index files where the same URL matches the generation criteria for multiple child sitemaps — appearing in both a "pages" sitemap and a "posts" sitemap, or in both a course sitemap and a general content sitemap. Automated generation produces these silently. SiteVitals captures up to 20 example URLs to make the issue actionable rather than just counting it.
10. Is the lastmod data accurate and present?
Of all the metadata attributes in the sitemap specification, lastmod is the only one that actually influences crawler behaviour. Google ignores changefreq and priority for indexing decisions. lastmod is different.
Google's guidance is explicit: "Google uses the lastmod value if it's consistently and verifiably accurate." That last qualifier matters. A lastmod timestamp that updates every time a sitemap is regenerated — regardless of whether the page content actually changed — is worse than no lastmod at all, because it trains the crawler to treat the signal as noise. The value only communicates "this page has changed, revisit it" when it genuinely reflects a meaningful update.
Accurate lastmod values also matter for AI systems. The same freshness signal that influences Google's crawl prioritisation is relevant to AI-powered discovery systems deciding which content to include in generated answers — an AI engine looking for current information will favour pages with accurate modification signals over those with static or absent timestamps.
SiteVitals flags invalid date formats, future dates (a common sign of a broken generation script), and sitemaps where a significant proportion of URLs are missing lastmod entirely.
11. Were there scan limits that affected the results?
On large sites, SiteVitals scans a sample rather than the full sitemap — up to 100 URLs for HTTP validation, up to 5,000 URL entries across child sitemaps. When those limits are hit, results are partial, and the report says so. This is surfaced as an informational note rather than a warning, because hitting a scan limit reflects the size of the sitemap, not a quality issue with it. A site with 40,000 well-formed URLs should not have its sitemap score affected because the scanner checked a representative portion of them.
Why this sits inside the AI Visibility score
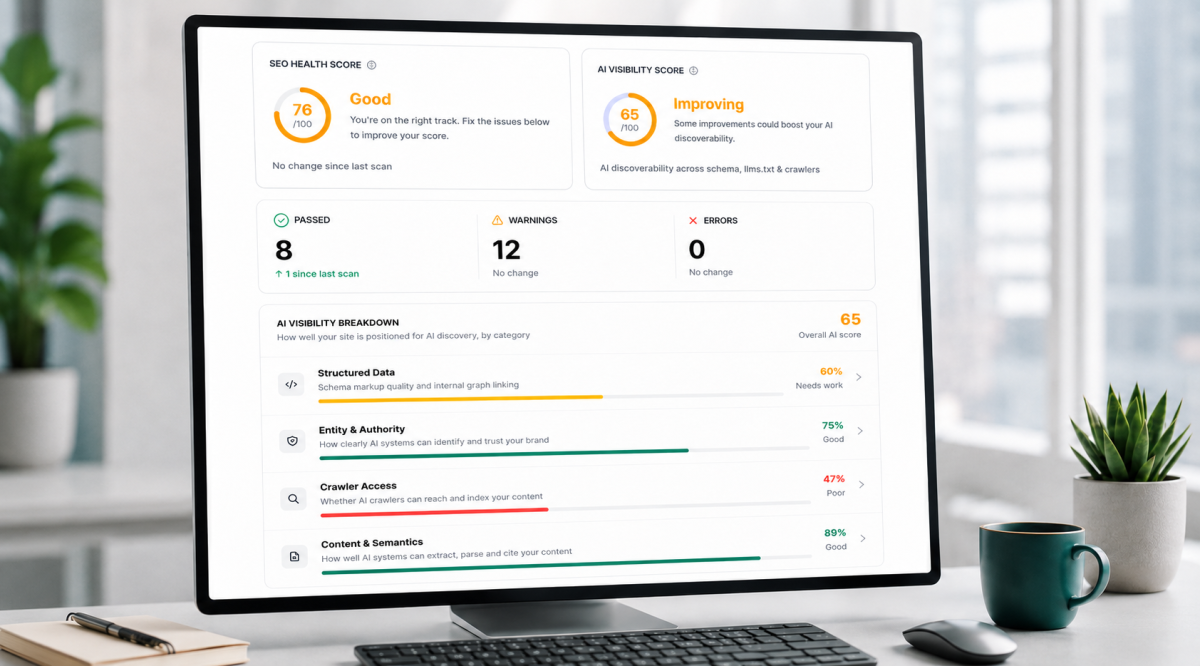
SiteVitals places XML Sitemap Quality within the Crawler Access category of the AI Visibility Breakdown — alongside AI Crawler Accessibility and llms.txt. The sitemap is the most explicit, structured inventory of a site's important content that exists, and any system trying to discover and index that content will use it.
Cloudflare's analysis puts training at around 80% of all AI crawling activity. These systems are not browsing passively — they are building retrieval indexes. A clean sitemap gives them an up-to-date, explicit map of your most important content. A broken or incomplete one leaves that discovery to chance.
The practical point for agencies is that sitemap quality degrades silently. Pages get added that do not match generation rules. HTTP URLs persist after HTTPS migrations. Child sitemaps in an index break without triggering any visible error. Lastmod timestamps get locked to a fixed date by a plugin update. None of these produce user-facing symptoms. All of them reduce the quality of the signal being sent to every crawler that visits the site — and they will continue to do so until something is actively checking for them. Which is why on-going SEO monitoring is so important. It's not a set and forget kind of thing unfortunately. Sitemaps deserve more respect than that.
Further reading

By Tom Freeman · Co-Founder & Lead Developer
Full-stack developer specialising in high-performance web applications and automated monitoring.